
User talk:Woodydebris37
Managing a conflict of interest
[edit]![]() Hello, Breitenbush Cascades. We welcome your contributions, but if you have an external relationship with the people, places or things you have written about on Wikipedia, you may have a conflict of interest (COI). Editors with a conflict of interest may be unduly influenced by their connection to the topic. See the conflict of interest guideline and FAQ for organizations for more information. We ask that you:
Hello, Breitenbush Cascades. We welcome your contributions, but if you have an external relationship with the people, places or things you have written about on Wikipedia, you may have a conflict of interest (COI). Editors with a conflict of interest may be unduly influenced by their connection to the topic. See the conflict of interest guideline and FAQ for organizations for more information. We ask that you:
- avoid editing or creating articles about yourself, your family, friends, company, organization or competitors;
- propose changes on the talk pages of affected articles (see the {{request edit}} template);
- disclose your conflict of interest when discussing affected articles (see WP:DISCLOSE);
- avoid linking to your organization's website in other articles (see WP:SPAM);
- do your best to comply with Wikipedia's content policies.
In addition, you must disclose your employer, client, and affiliation with respect to any contribution which forms all or part of work for which you receive, or expect to receive, compensation (see WP:PAID).
Also please note that editing for the purpose of advertising, publicising, or promoting anyone or anything is not permitted. Thank you. 331dot (talk) 17:55, 15 March 2019 (UTC)
To other admins, I'm working with this user at the Teahouse and I would request that they not be blocked at this time. 331dot (talk) 18:08, 15 March 2019 (UTC)
March 2019
[edit]![]() Hello and welcome to Wikipedia. When you add content to talk pages and Wikipedia pages that have open discussion (but never when editing articles), such as at Wikipedia:Teahouse, please be sure to sign your posts. There are two ways to do this. Either:
Hello and welcome to Wikipedia. When you add content to talk pages and Wikipedia pages that have open discussion (but never when editing articles), such as at Wikipedia:Teahouse, please be sure to sign your posts. There are two ways to do this. Either:
- Add four tildes ( ~~~~ ) at the end of your comment, or
- With the cursor positioned at the end of your comment, click on the signature button
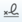 located above the edit window.
located above the edit window.
This will automatically insert a signature with your username or IP address and the time you posted the comment. This information is necessary to allow other editors to easily see who wrote what and when.
Thank you. Drm310 🍁 (talk) 19:01, 15 March 2019 (UTC)
Welcome!
[edit]Hello, Breitenbush Cascades, and welcome to Wikipedia! Thank you for your contributions. I hope you like the place and decide to stay. Here are a few links to pages you might find helpful:
You may also want to complete the Wikipedia Adventure, an interactive tour that will help you learn the basics of editing Wikipedia. You can visit the Teahouse to ask questions or seek help.
Please remember to sign your messages on talk pages by typing four tildes (~~~~); this will automatically insert your username and the date. If you need help, check out Wikipedia:Questions, ask me on my talk page, or , and a volunteer should respond shortly. Again, welcome! Polyamorph (talk) 19:18, 15 March 2019 (UTC)
- Globally renamed to Woodydebris37, as per request. GABgab 23:29, 15 March 2019 (UTC)
Your thread has been archived
[edit]Hi Woodydebris37! You created a thread called Archival by Lowercase sigmabot III, notification delivery by Muninnbot, both automated accounts. You can opt out of future notifications by placing
|